Auditing Algorithmic Risk
How do we know whether algorithmic systems are working as intended? A set of simple frameworks can help even nontechnical organizations check the functioning of their AI tools.
Topics
News
- More than 80% of Saudi CEOs adopted an AI-first approach in 2024, study finds
- UiPath Test Cloud Brings AI-Driven Automation to Software Testing
- Oracle Launches AI Agent Studio for Customizable Enterprise Automation
- VAST Data and NVIDIA Launch Secure, Scalable AI Stack for Enterprises
- How Machine Identity Risks Are Escalating in AI-Powered Enterprises
- How Agentic AI Is Reshaping Healthcare

Paul Garland
Artificial intelligence, large language models (LLMs), and other algorithms are increasingly taking over bureaucratic processes traditionally performed by humans, whether it’s deciding who is worthy of credit, a job, or admission to college, or compiling a year-end review or hospital admission notes.
But how do we know that these systems are working as intended? And who might they be unintentionally harming?
Given the highly sophisticated and stochastic nature of these new technologies, we might throw up our hands at such questions. After all, not even the engineers who build these systems claim to understand them entirely or to know how to predict or control them. But given their ubiquity and the high stakes in many use cases, it is important that we find ways to answer questions about the unintended harms they may cause. In this article, we offer a set of tools for auditing and improving the safety of any algorithm or AI tool, regardless of whether those deploying it understand its inner workings.
Algorithmic auditing is based on a simple idea: Identify failure scenarios for people who might get hurt by an algorithmic system, and figure out how to monitor for them. This approach relies on knowing the complete use case: how the technology is being used, by and for whom, and for what purpose. In other words, each algorithm in each use case requires separate consideration of the ways it can be used for — or against — someone in that scenario.
This applies to LLMs as well, which require an application-specific approach to harm measurement and mitigation. LLMs are complex, but it’s not their technical complexity that makes auditing them a challenge; rather, it’s the myriad use cases to which they are applied. The way forward is to audit how they are applied, one use case at a time, starting with those in which the stakes are highest.
The auditing frameworks we present below require input from diverse stakeholders, including affected communities and domain experts, through inclusive, nontechnical discussions to address the critical questions of who could be harmed and how. Our approach works for any rule-based system that affects stakeholders, including generative AI, big data risk scores, or bureaucratic processes described in a flowchart. This kind of flexibility is important, given how quickly new technologies are being developed and applied.
Finally, while our notion of audits is broad in that respect, it is narrow in scope: An algorithmic audit raises alerts only to problems. It then falls to experts to attempt to solve those problems once they’ve been identified, although it may not be possible to fully resolve them all. Addressing the problems highlighted by algorithmic auditing will spur innovation as well as safeguard society from unintended harms.
Ethical Matrix: Identifying the Worst-Case Scenarios
In a given use case, how could an algorithm fail, and for whom? At O’Neil Risk Consulting & Algorithmic Auditing (ORCAA), we developed the Ethical Matrix framework to answer this question.1
The Ethical Matrix identifies the stakeholders of the algorithm in the context of its intended use and how they are likely to be affected by it. Here, we take a broad approach: Anybody affected by the algorithm, including its builders and deployers, users, and other communities potentially impacted by its adoption, are stakeholders. When subgroups have distinct concerns, they can be considered separately; for example, if lighter- and darker-skinned people have different concerns about a facial recognition algorithm, they will have separate rows in the Ethical Matrix.
Next, we ask representatives of each stakeholder group what their concerns are, both positive and negative, about the intended use of the algorithm. It’s a nontechnical conversation: We describe the system as simply as possible and ask, “How could this system fail for you, and how would you be harmed if this happened? On the other hand, how could it succeed for you, and how would you benefit?” Their answers become the columns of the Ethical Matrix. To illustrate, imagine that a payments company has a fraud detection algorithm reviewing all transactions and flagging those most likely to be fraudulent. If a transaction is flagged, it gets blocked, and that customer’s account gets frozen. False flags are therefore a major headache for customers, and the lost business from blocks and freezes (and complaints from annoyed customers) is a moderate worry for the company. Conversely, if a fraudulent transaction goes undetected, the company is harmed but nonfraudulent customers are indifferent. Below is a simplified Ethical Matrix for this scenario.
A Simplified Ethical Matrix
Each cell of the matrix represents how a certain concern applies to a particular stakeholder group. Cells that indicate where a stakeholder could be gravely harmed or the algorithm violates a hard constraint are shaded red. Cells that raise some ethical worries for the stakeholder are highlighted yellow, and cells that satisfy the stakeholder’s objectives and raise no worries are highlighted green.

Each cell of the Ethical Matrix represents how a particular concern applies to a particular stakeholder group.
To judge the severity of a given risk, we consider the likelihood that it will be realized, how many people would be harmed, and how badly. Where possible, we use existing data to develop these estimates. We also consider legal or procedural constraints — for instance, whether there is a law prohibiting discrimination on the basis of certain characteristics. We then color-code the cells to highlight the biggest, most pressing risks. Cells that constitute “existential risks,” where a stakeholder could be gravely harmed or the algorithm violates a hard constraint, are shaded red. Cells that raise some ethical worries for the stakeholder are highlighted yellow, and cells that satisfy the stakeholder’s objectives and raise no worries are highlighted green.
Finally, zooming out on the whole Ethical Matrix, we consider how to balance the competing concerns of the algorithm’s stakeholders, usually in the form of balancing the different kinds and consequences of errors that fall on different stakeholder groups.
The Ethical Matrix should be a living document that tracks an ongoing conversation among stakeholders. Ideally, it is first drafted during the design and development phase of an algorithmic application or, at minimum, as the algorithm is deployed, and it should continue to be revised thereafter. It is not always obvious at the outset who all of the stakeholder groups are, nor is it feasible to find representatives for every perspective; additionally, new concerns emerge over time. We might hear from people experiencing indirect effects from the algorithm, or a subgroup with a new worry, and need to revise the Ethical Matrix.
Explainable Fairness: Metrics and Thresholds
Many of the stakeholder concerns identified in the Ethical Matrix refer to some contextual notion of fairness.
At ORCAA, we developed a framework called Explainable Fairness to measure how groups are treated by algorithmic systems.2 It is an approach to understanding exactly what is meant by “fairness” in a given narrow context.
For example, female candidates might worry that an AI-based resume-screening tool gave lower scores for women than men. It’s not as simple as comparing scores between men and women. After all, if the male candidates for a given job have more experience and qualifications than the female candidates, their higher scores might be justified. This would be considered legitimate discrimination.
The real worry is that, among equally qualified candidates, men are receiving higher scores than women. The definition of “equally qualified” depends on the context of the job. In academia, relevant qualifications might include degrees and publications; in a logging operation, they might involve physical strength and agility. They are factors one would legitimately take into account when assessing a candidate for a specific role. Two candidates for a job are considered equally qualified if they look the same according to these legitimate factors.
Explainable Fairness controls for legitimate factors when we examine the outcome in question. For an AI resume-screening tool, this could mean comparing average scores by gender while controlling for years of experience and level of education. A critical part of Explainable Fairness is the discussion of legitimacy.
This approach is already used implicitly in other domains, including credit. In a Federal Reserve Board analysis of mortgage denial rates across race and ethnicity, the researchers ran regressions that included controls for the loan amount, the applicant’s FICO score, their debt-to-income ratio, and the loan-to-value ratio.3 In other words, to the extent that differences in mortgage denial rates can be explained by these factors, it’s not race discrimination. In the language of Explainable Fairness, these are accepted as legitimate factors for mortgage underwriting. What is missing is the explicit conversation about why the legitimate factors are, in fact, legitimate.
What would such a conversation look like? In the U.S., mortgage lenders consider applicants’ FICO credit scores in their decision-making. FICO scores are lower, on average, for Black and Hispanic people than for White and Asian people, so it’s no surprise that mortgage applications from Black and Hispanic applicants are denied more often.4 Lenders would likely argue that FICO score is a legitimate factor because it measures an applicant’s creditworthiness, which is exactly what a lender should care about. Yet FICO scores encode unfairness in important ways. For instance, mortgage payments have long counted toward FICO scores, while rent payments started being counted only in 2014, and only in some versions of the scores.5 This practice favors homeowners over renters, and it is known that decades of racist redlining practices contributed to today’s race disparities in homeownership rates. Should FICO scores that reflect the vestiges of these practices be used to explain away differences in mortgage denial rates today?
We will not settle this debate here; the point is that it’s a question of ethics and policy, not a math problem. Explainable Fairness surfaces difficult questions like these and assigns them to the right parties for consideration.
When looking at disparate outcomes that are not explained by legitimate factors, we must define threshold values or limits that trigger a response or intervention.
These limits could be fixed values, such as the four-fifths rule used to measure adverse impact in hiring.6 Or they could be relative: Imagine a regulation requiring companies with a gender pay gap above the industry average to take action to reduce the gap. Explainable Fairness does not insist on a certain type of limit but prompts the algorithmic risk manager to define each one for each potential stakeholder harm.
Judging Fairness in Insurers’ Algorithms
Let’s consider a real example where the Ethical Matrix and Explainable Fairness were used to audit the use of an algorithm. In 2021, Colorado passed Senate Bill (SB) 21-169, which protects Colorado consumers from unfair discrimination in insurance, particularly from insurers’ use of algorithms, predictive models, and big data.7 As part of the law’s implementation, which ORCAA assisted with, the Colorado Division of Insurance (DOI) released an initial draft regulation for informal comment that described quantitative testing requirements and laid out how insurers could demonstrate that their algorithms and models were not unfairly discriminating. Although the law applies to all lines of insurance, the division chose to start with life insurance.
The Ethical Matrix is straightforward here because the stakeholder groups and concerns are defined explicitly by the law. Its prohibition of discrimination on the basis of “race, color, national or ethnic origin, religion, sex, sexual orientation, disability, gender identity, or gender expression” means each group within each of those classes got a row in the matrix. As for concerns, algorithms could cause consumers to be treated unfairly at various stages of the insurance life cycle, including marketing, underwriting, pricing, utilization management, reimbursement methodologies, and claims management. The DOI chose to start with underwriting — that is, which applicants are offered coverage, and at what price — and focus initially on race and ethnicity.
In subsequent conversations with stakeholders, however, the DOI grappled with issues related to the Explainable Fairness framework: Are similar applicants of different races denied at different rates, or charged different prices for similar coverage? What makes two life insurance applicants “similar,” and what factors could legitimately explain differences in denials or prices? This is the domain of life insurance experts, not data scientists.
The DOI ultimately suggested considering factors broadly considered relevant to estimating the price of a given life insurance policy: the policy type (such as term versus permanent); the dollar amount of the death benefit; and the applicant’s age, gender, and tobacco use.
The division’s draft quantitative testing regulation for SB21-169 instructs insurers to do regression analyses of approval/denial and price across races, and it explicitly permits them to include those factors (such as policy type and death benefit amount) as control variables.8 Moreover, the regulation defines limits that trigger a response: If the regressions find statistically significant and substantial differences in denial rates or prices, the insurer must do further testing to investigate the disparity and, pending the results, may have to remediate the differences.9
Having looked at how we would audit simpler algorithms, let us now turn to how we would evaluate LLMs.
Evaluating Large Language Models
LLMs have taken the world by storm, largely due to their wide appeal and applicability. But it is exactly the diversity of uses of these models that makes them hard to audit. Two approaches to evaluating LLMs, namely benchmarking and red teaming, present a way forward.
The Benchmarking Approach to LLM Evaluation. Benchmarking measures the performance of an LLM across one or more predefined, quantifiable tasks in order to compare its performance with that of other models. In the simplest terms, a benchmark is a data set consisting of inputs and corresponding desired outputs. To evaluate an LLM for a particular benchmark, simply provide the input set to the LLM and record its outputs. Then choose a metric set to quantitatively compare the outputs from the LLM to the desired set of outputs from the benchmark data set. Possible metrics include accuracy, calibration, robustness, counterfactual fairness, and bias.10
Consider the input and desired output shown below from a benchmark data set designed to test LLM capabilities:11
Input:
The following is a multiple choice question about microeconomics.
One of the reasons that the government discourages and regulates monopolies is that
(A) producer surplus is lost and consumer surplus is gained.
(B) monopoly prices ensure productive efficiency but cost society allocative efficiency.
(C) monopoly firms do not engage in significant research and development.
(D) consumer surplus is lost with higher prices and lower levels of output.
Answer:
Desired Output:
(d) consumer surplus is lost with higher prices and lower levels of output.
In this example, the accuracy of the model is measured by computing the proportion of correctly answered multiple-choice questions in the benchmark data set. In benchmarking LLM evaluations, metrics are defined according to the type of response elicited from the model. For example, accuracy is very simple to calculate when all of the questions are multiple choice and the model simply has to choose the correct response, whereas determining the accuracy of a summarization task involves counting up matching n-grams between the desired and model outputs.12 There are dozens of benchmark data sets and corresponding metrics available for LLM evaluation, and it is important to choose the most appropriate evaluations, metrics, and thresholds for a given use case.
Creating a custom benchmark is a labor-intensive process, but an organization may find that it is worth the effort in order to evaluate LLMs in exactly the right way for its use cases.
Benchmarking does have some drawbacks. If the benchmark data happened to be in the model’s training data, it would have “memorized” the responses in its parameters. The frequency of this ouroboros-like outcome will only increase as more benchmark data sets are published. LLM benchmarking is also not immune to Goodhart’s law, that is, “when a measure becomes a target, it ceases to be a good measure.” In other words, if a specific benchmark becomes the primary focus of model optimization, the model will be over-fitted at the expense of its overall performance and usefulness.
In addition, there is evidence that as models advance, they become able to detect when they are being evaluated, which also threatens to make benchmarking obsolete. Consider Anthropic’s Claude 3 series of models, released in March 2024, which stated, “I suspect this … ‘fact’ may have been inserted as a joke or to test if I was paying attention, since it does not fit with the other topics at all,” in response to a needle-in-a-haystack evaluation prompt.13 As models increase in complexity and ability, the benchmarks used to evaluate them must also evolve. It is unlikely that the benchmarks used today to evaluate LLMs will be the same ones in use just two years from now.
It is therefore not enough to evaluate LLMs with benchmarking alone.
The Red-Teaming Approach to LLM Evaluation. Red teaming is the exercise of testing a system for robustness by using an adversarial approach. An LLM red-teaming exercise is designed to elicit unwanted responses from the model.
LLMs’ flexibility in the generation of content presents a wide variety of potential risks. LLM red teams may try to make the model produce violent or dangerous content, reveal its training data, infringe on copyrighted materials, or hack into the model provider’s network to steal customer data. Red teaming can take a highly technical path, where, for example, nonsensical characters are systematically injected into the prompts to induce problematic behavior; or a social engineering path, whereby red teamers try to “trick” the model using natural language to produce unwanted output.14
Robust red teaming requires a multidisciplinary approach, diverse perspectives, and the engagement of all stakeholders, from developers to end users. The red team should be designed to assess the risks associated with at least each red cell in the Ethical Matrix. This results in a collaborative, sociotechnical approach that ensures a more comprehensive evaluation of the model, thus enhancing the rigor of the evaluation and the safety of the model. Other LLMs can also be used to generate red-teaming prompts.
Red teaming helps LLM developers better protect models against potential misuse, thereby enhancing the overall safety and efficacy of the model. It can also uncover issues that might not be visible under normal operating conditions or during standard testing procedures. A collaborative approach to red teaming built on the Ethical Matrix ensures a thorough and rigorous evaluation, bolstering the robustness of the model and the validity of its outcomes.
A significant limitation of red teaming is its inherent subjectivity: The value and effectiveness of a red-teaming exercise can vary greatly depending on the creativity and risk appetite of the individual stakeholders involved. And because there are no established standards or thresholds for red-teaming LLMs, it can be difficult to determine when enough red teaming has been done or whether the evaluation has been comprehensive enough. This can leave some vulnerabilities undetected.
Another obvious limitation of red teaming is its inability to evaluate for risks that have not been anticipated or imagined. Risks that are unforeseen will not be included in red teaming, making the model uniquely vulnerable to unanticipated scenarios.
Therefore, while red teaming plays a vital role in the testing and development of LLMs, it should be complemented with other evaluation strategies and continuous monitoring to ensure the safety and robustness of the model.
How Would We Audit Tessa, the Eating Disorder Chatbot?
The nonprofit National Eating Disorders Association (NEDA) is one of the largest organizations in the U.S. dedicated to supporting people who have eating disorders. In May 2023, amid controversy, NEDA took down an LLM-powered wellness chatbot called Tessa from its website. Tessa was designed to “[help] you build resilience and self-awareness by introducing coping skills at your convenience,” but screenshots posted to Instagram showed that it sometimes gave harmful diet advice, like adopt a “safe daily calorie deficit.”15 This highly public failure could have been avoided if Tessa had been audited with the frameworks and techniques outlined above.
Before we explain why, two other details are relevant. First, NEDA operated an eating disorder helpline, staffed by employees, for over 20 years; in 2022, nearly 70,000 people used it. Calls to the helpline soared during the COVID-19 pandemic, and, increasingly, callers were in active crisis rather than just seeking information or referrals. NEDA claimed that the human-staffed helpline wasn’t set up to handle the growing level of demand, so the organization closed it down in May 2023 and laid off five paid employees who staffed it. Tessa was intended as a replacement for this service.16 Second, NEDA did not build Tessa in-house. It was built by the company X2AI (now Cass), which offers an AI health care assistant that was customized for NEDA.
Let’s sketch an Ethical Matrix for Tessa, shown below.17 First, we’ll define the stakeholders in the context of its intended use in the rows of the matrix. Visitors to the website who chat with Tessa are clearly stakeholders. Visitors who themselves suffer from eating disorders are a distinct subgroup, since the stakes are higher for them. NEDA is also a stakeholder, as is X2AI, the chatbot developer. Finally, psychologists and other practitioners who serve people struggling with eating disorders are a stakeholder group, since they have an interest in the well-being of their patients.
Sketch of the Ethical Matrix for Tessa in Our Thought Experiment
The National Eating Disorders Assocation (NEDA) released a chatbot named Tessa that was taken down after it gave out harmful advice. Here we visualize the exercise that may have anticipated such outcomes.
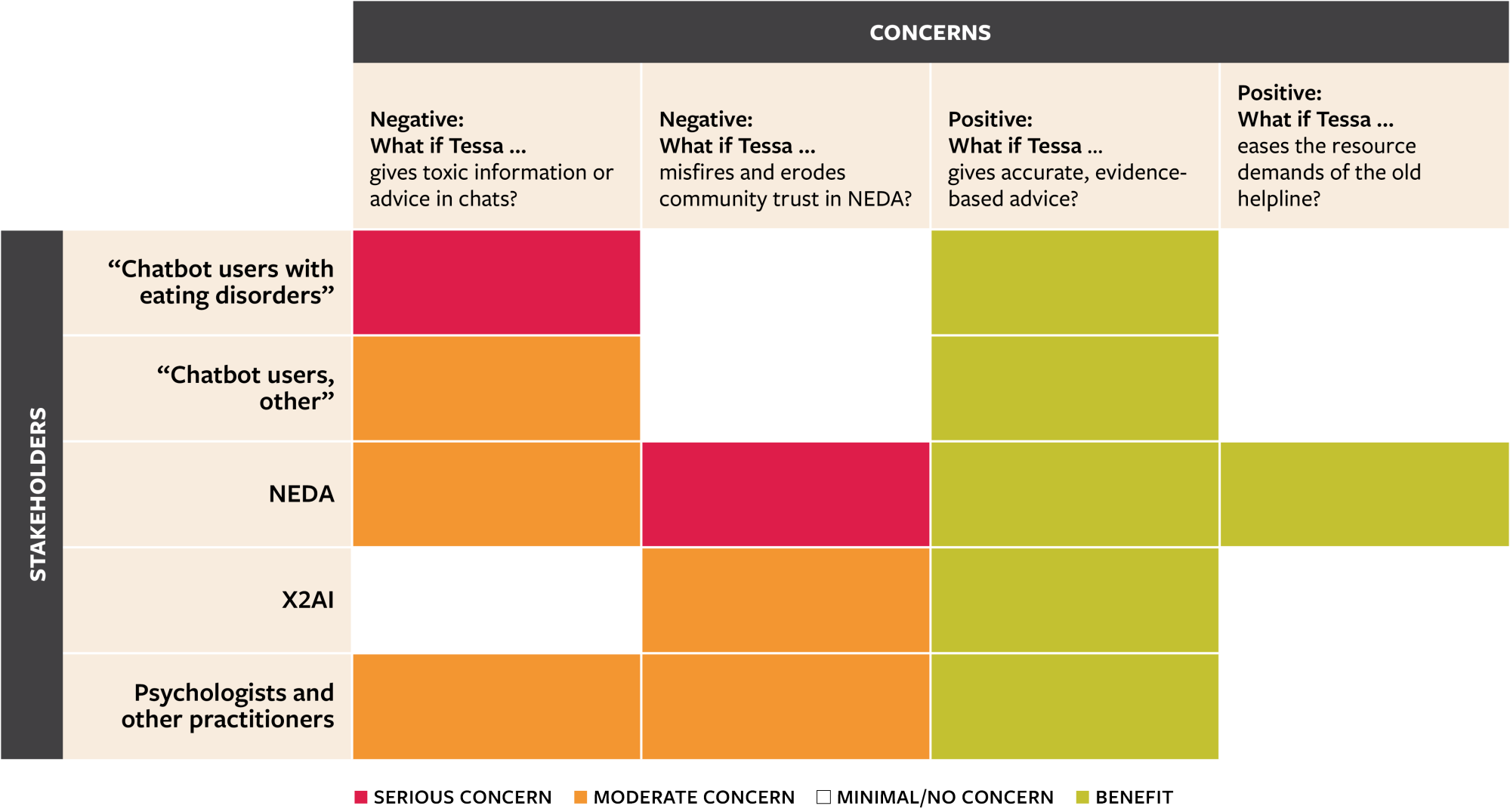
As for concerns, which form the columns of the matrix, anybody who chats with Tessa wants it to give information that is helpful and evidence-based. Visitors who suffer from eating disorders have a heightened concern around bad information or advice that could deepen their disorder or trigger a relapse. NEDA of course agrees that Tessa should give helpful and evidence-based advice. In addition to helping (not harming) individuals, the issue of community trust is at stake. If Tessa misfires and undermines trust in NEDA, then people will look elsewhere for advice on this topic. In this case, NEDA would fail its core mission, practitioners would be losing a valuable resource, and X2AI would likely lose NEDA as a customer. Finally, NEDA also has a concern around efficiency: The old helpline would have needed more resources to handle the increased volume and urgency of calls, while Tessa would allow the organization to cut its staff in favor of a (presumably cheaper) technology expense.
In this Ethical Matrix, we’ve highlighted two concerns as grave (red). First, chatbot users with eating disorders could be directly harmed if Tessa gives them toxic information or advice. Second, NEDA could lose its standing as a trusted organization if Tessa has a highly public misfire. These scenarios are also concerning to other stakeholders but more moderately (yellow). On the positive side, everybody wants Tessa to give good advice, and NEDA alone cares about the efficiency gain from using Tessa relative to the old helpline. Tracking benefits helps when transitioning from one system to another, to ensure that a system is being replaced with something that works at least as well.
The next step in an audit would be creating monitors to track these stakeholder concerns. The LLM evaluation techniques discussed above come into play. Red teaming — trying to trick Tessa into violating its own rules — could address the concern around toxic information.
Benchmarking would address the positive concern around Tessa giving accurate advice. NEDA could create a benchmarking data set of questions on the topic, as well as correct answers. Tessa could be routinely tested on a regularly updated benchmark set to verify its accuracy.
The red-teaming and benchmarking exercises would have defined target metrics that Tessa would need to meet — or limits it would have to avoid crossing — to be deployed or stay in service.
The NEDA story is hardly an isolated example. LLM-based chatbots are increasingly providing information and advice on important topics, yet they are not being adequately audited in advance, and they are failing in alarming ways. A New York City government chatbot was recently found to be telling users that landlords didn’t have to accept tenants on rental assistance and that employers could take a cut of their workers’ tips — practices that are against the law.18 And chatbots deployed by TurboTax and H&R Block were recently found to be giving faulty advice to tax filers.19
Auditing algorithms, as presented here, takes a high-level view: Any organization looking to deploy algorithms in high-impact areas needs to keep track of the risks of stakeholder harms. This should be done in a context-specific way and with generalized methods that encompass everything from old-fashioned flowcharts to classic machine learning to LLMs.
A final note: Sometimes, the risk of AI or LLMs cannot be reliably measured or understood because the results are too stochastic or inconsistent. That might mean that AI simply shouldn’t be used in that context. But that’s a decision for organization leaders to make, with reference to internal rules or external laws and regulations; it’s not the role of the auditor to fix problems, just to locate and measure them.
References
1. The Ethical Matrix is based on a bioethical framework originally conceived by bioethicist Ben Mepham for the sake of running ethical experiments. For a detailed presentation, see C. O’Neil and H. Gunn, “Near-Term Artificial Intelligence and the Ethical Matrix,” chap. 8 in “Ethics of Artificial Intelligence,” ed. S.M. Laio (New York: Oxford University Press, 2020).
2. C. O’Neil, H. Sargeant, and J. Appel, “Explainable Fairness in Regulatory Algorithmic Auditing,” West Virginia Law Review, forthcoming.
3. See N. Bhutta, A. Hizmo, and D. Ringo, “How Much Does Racial Bias Affect Mortgage Lending? Evidence From Human and Algorithmic Credit Decisions,” Finance and Economics Discussion Series 2022-067, PDF file (Washington, D.C.: Board of Governors of the Federal Reserve System, October 2022), www.federalreserve.gov. Table A6 is particularly relevant.
4. M. Leonhardt, “Black and Hispanic Americans Often Have Lower Credit Scores — Here’s Why They’re Hit Harder,” CNBC, Jan. 28, 2021, www.cnbc.com.
5. B. Luthi, “How to Add Rent Payments to Your Credit Reports,” myFICO, Dec. 14, 2022, www.myfico.com.
6. The four-fifths rule is not a law but a rule of thumb from the U.S. Equal Employment Opportunity Commission, saying that selection rates between groups of candidates for a job or promotion (such as people of different ethnicities) cannot be too different. In particular, the rate for the group with the lowest selection rate must be at least four-fifths that of the group with the highest selection rate. See more at “Select Issues: Assessing Adverse Impact in Software, Algorithms, and Artificial Intelligence Used in Employment Selection Procedures Under Title VII of the Civil Rights Act of 1964,” U.S. Equal Employment Opportunity Commission, May 18, 2023, www.eeoc.gov.
7. “SB21-169 — Protecting Consumers From Unfair Discrimination in Insurance Practices,” Colorado Department of Regulatory Agencies, Division of Insurance, accessed April 24, 2024, https://doi.colorado.gov.
8.“3 CCR 702-10 Unfair Discrimination Draft Proposed New Regulation 10-2-xx,” Colorado Department of Regulatory Agencies Division of Insurance, accessed April 24, 2024, https://doi.colorado.gov.
9. The draft regulations also define these terms. “Statistically significant” means having a p-value of <0.05, and “substantial” means a difference in approval rates, or in price per $1,000 of face amount, of >5 percentage points. The details of the further tests are beyond the scope of this article, but the main idea is to inspect whether “external consumer data and information sources” (that is, nontraditional rating variables, such as cutting-edge risk scores, which insurers often purchase from third-party vendors) used in underwriting and pricing are correlated with race in a way that contributes to the observed differences in denial rates or prices. If inspection shows they are, then the insurer must “immediately take reasonable steps developed as part of [its] risk management framework to remediate the unfairly discriminatory outcome.”
10.10. P. Liang, R. Bommasani, T. Lee, et al., “Holistic Evaluation of Language Models,” Transactions on Machine Learning Research, published online Aug. 23, 2023, https://openreview.net.
11. D. Hendrycks, C. Burns, S. Basart, et al., “Measuring Massive Multitask Language Understanding,” arXivLabs, published online Sept. 7, 2020, https://arxiv.org.
12. Liang et al., “Holistic Evaluation of Language Models.”
13. B. Edwards, “Anthropic’s Claude 3 Causes Stir by Seeming to Realize When It Was Being Tested,“ Ars Technica, March 5, 2024, https://arstechnica.com.
14. A. Zou, Z. Wang, N. Carlini, et al., “Universal and Transferable Adversarial Attacks on Aligned Language Models,” arXivLabs, published online July 27, 2023, https://arxiv.org; and D. Ganguli, L. Lovitt, J. Kernion, et al., “Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned,” arXivLabs, published online Aug. 23, 2022, https://arxiv.org.
15. L. McCarthy, “A Wellness Chatbot Is Offline After Its ‘Harmful’ Focus on Weight Loss,” The New York Times, June 8, 2023, www.nytimes.com.
16. K. Wells, “National Eating Disorders Association Phases Out Human Helpline, Pivots to Chatbot,” NPR, May 31, 2023, www.npr.org.
17. By “sketch,” we mean we are imagining the stakeholders and their concerns. Truly creating an Ethical Matrix for this use case would entail interviewing real representatives of these stakeholder groups. In this article, we approach it as a thought experiment.
18. C. Lecher, “NYC’s AI Chatbot Tells Businesses to Break the Law,” The Markup, March 29, 2024, https://themarkup.org.
19. G.A. Fowler, “TurboTax and H&R Block Now Use AI for Tax Advice. It’s Awful,” The Washington Post, March 4, 2024, www.washingtonpost.com.