How LLMs are Shaping Enterprise-Scale Applications
By implementing structured frameworks such as AI agents, integrating structured prompts, and incorporating human interaction patterns and guardrails, businesses can navigate LLMs' creative potential while ensuring reliability.
News
- CEOs Recognize AI’s Potential but Fear Knowledge Gaps, Study Finds
- Core42 and Qualcomm Unveil AI Playground to Accelerate Adoption in UAE
- Customer Centricity Summit & Awards Explores Brand-Customer Relationships in KSA
- GITEX Global 2024 to Showcase Global Innovation, Investment, and Cybersecurity Trends
- The Perfectly Imperfect Start of Disruptive Innovations
- GovTech Conclave to Explore Cutting-Edge Solutions for Modern Governance

[Image source: Krishna Prasad/MITSMR Middle East]
Are Large Language Models (LLMS) unreasoning, stochastic parrots that merely regurgitate their training data? For many, the answer depends largely on which side of the debate you find yourself.
The term stochastic parrots was coined in 2021 by Emily M. Bender in a paper she co-authored with three others. Bender explains that the mix of human biases and seemingly coherent language heightens the potential for automation bias, deliberate misuse, and amplification of a hegemonic worldview.1 The term has since become widely used by critics of LLMs to highlight their tendency to generate text by probabilistically predicting word sequences without true understanding.
Those in favor contend that, despite its imperfections, the current generation of AI marks the inception of artificial general intelligence.
Blaise Agüera y Arcas, Google VP of engineering and Peter Norvig, computer scientist and Distinguished Education Fellow at the Stanford Institute for Human-Centered AI, in an article published in Noema, say “today’s frontier models perform competently even on novel tasks they were not trained for, crossing a threshold that previous generations of AI and supervised deep learning systems never managed. Decades from now, they will be recognized as the first true examples of AGI.”2

Albert Phelps, prompt engineer and co-founder of tomoro.ai, presenting a keynote on Generative AI at Enterprise-Scale at the NextTech Summit.
With AI becoming a “god-like” thing, the voices of both proponents and critics are growing louder. This leads to a sharp divide in opinions about the LLMs that drive much of AI’s advancements, with strong arguments on both sides.
However, the best way to think about LLMs lies between the extremes of seeing them as mere “stochastic parrots” or “superhuman reasoners”.
This notion of LLMs being just “stochastic parrots” is demonstrably false, especially when considering the principle of transfer learning, said Albert Phelps, a prompt engineer and co-founder of tomoro.ai, a consultancy start-up specializing in helping businesses adapt to automation, machine learning, and AI.
When a LLM is trained on code, it becomes markedly better at verbal reasoning, mathematical reasoning, and entity recognition. This indicates a level of generalization within these models, particularly in their deeper layers that we’re not able to see.
However, it is equally crucial to recognize that current LLMs are not superhuman reasoners. “They can be easily tripped up and, in many ways, are less capable or clever than school children,” Phelps said during his keynote at NextTech Summit 2024. An example is the “reversal curse,” where a language model can identify Tom Cruise’s mother but fails to recognize her name when queried in reverse.
Professor Munther A. Dahleh, Director of the MIT Institute for Data, Systems, and Society, offered a more nuanced perspective on the statistical accuracy of LLMs during a presentation last year.
“The statistical accuracy of a language model is about the next word being a legitimate English word and a legitimate English sentence. However, the statistical accuracy in the word does not translate to statistical accuracy in the idea, in the concept,” he said. This statistical prowess can sometimes produce insightful results, but it also risks generating misleading or incorrect information that appears convincing.
He then explained the statistical accuracy of a phenomenon — like if one wants to understand protein folding, or impact of a new drug. Integrating relevant data about the phenomenon with texts discussing similar questions can significantly enhance understanding. For instance, when studying the efficacy of a COVID-19 vaccine, incorporating general vaccine data helps identify confounders—factors that might affect results based on variables like age or health conditions. This approach, federated learning or transfer learning, allows for a more comprehensive and accelerated understanding of complex phenomena.
So, for enterprises, what’s the best framing and way to think about LLMs?
Andrej Karpathy, Co-founder of OpenAI, famously said, “In a certain sense, hallucination is all large language models do. They are dream machines.” This perspective is particularly relevant for enterprises concerned about hallucinations in LLMs. Instead of viewing hallucinations solely as a bug, they can be seen as a feature, part of the model’s inherent creativity, added Phelps. “When building enterprise-grade applications with LLMs, we’re trying to actually get them to simulate a helpful, accurate, trustworthy assistant.”
At this stage, LLMs are simulators.
For enterprises, LLMs alone are not enough. The language model must be grounded, role-tuned, and armed with prompts, personality, knowledge, and tools.
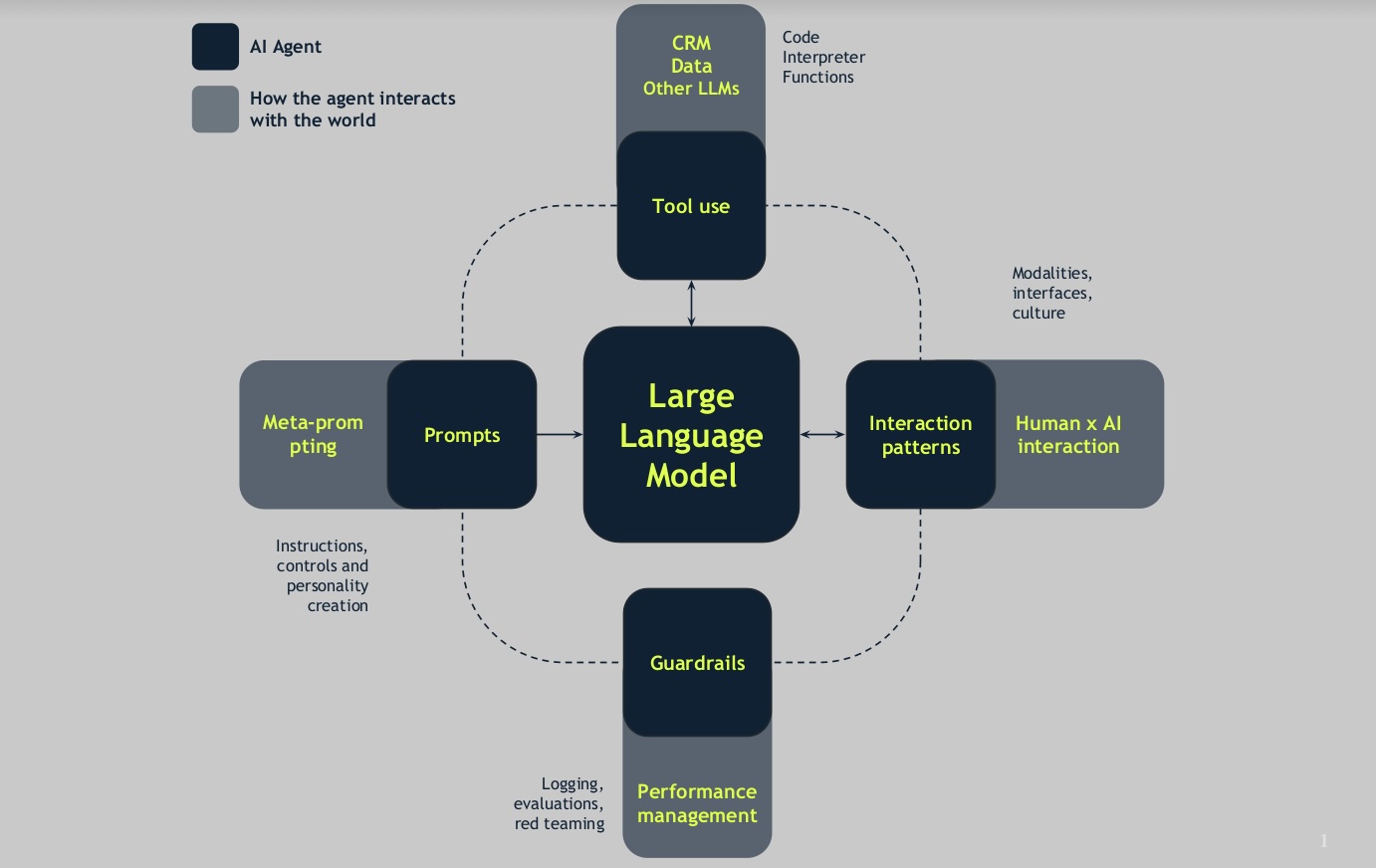
And the best way to do this is with AI agents. At the center of these agents are LLMs integrated with structured prompts, human interaction patterns, tool use, and guardrails.
AI Agents
At the center of these agents are LLMs integrated with structured prompts, human interaction patterns, tool use, and guardrails.
Source: tomoro.ai
How does the agent interact with the world, then?
- Meta prompting: LLMs generate instructions, controls, and the model’s personality to be created.
- Human Interaction Modality: Considers how users interact with the agent (chat, UI integration, etc.).
- Tool Use: Integrating the agent with CRM, data sources, other AI models, or machine learning capabilities.
- Guardrails: LLM systems are non deterministic, so guardrails are implemented through:
- Logging: Monitoring agent activity.
- Evaluation: Assessing agent performance and safety.
- Adversarial Prompting & Red Teaming: Testing the agent for vulnerabilities.
This structured approach allows LLMs to simulate a helpful, accurate, trustworthy assistant, thereby delivering real value to enterprises.
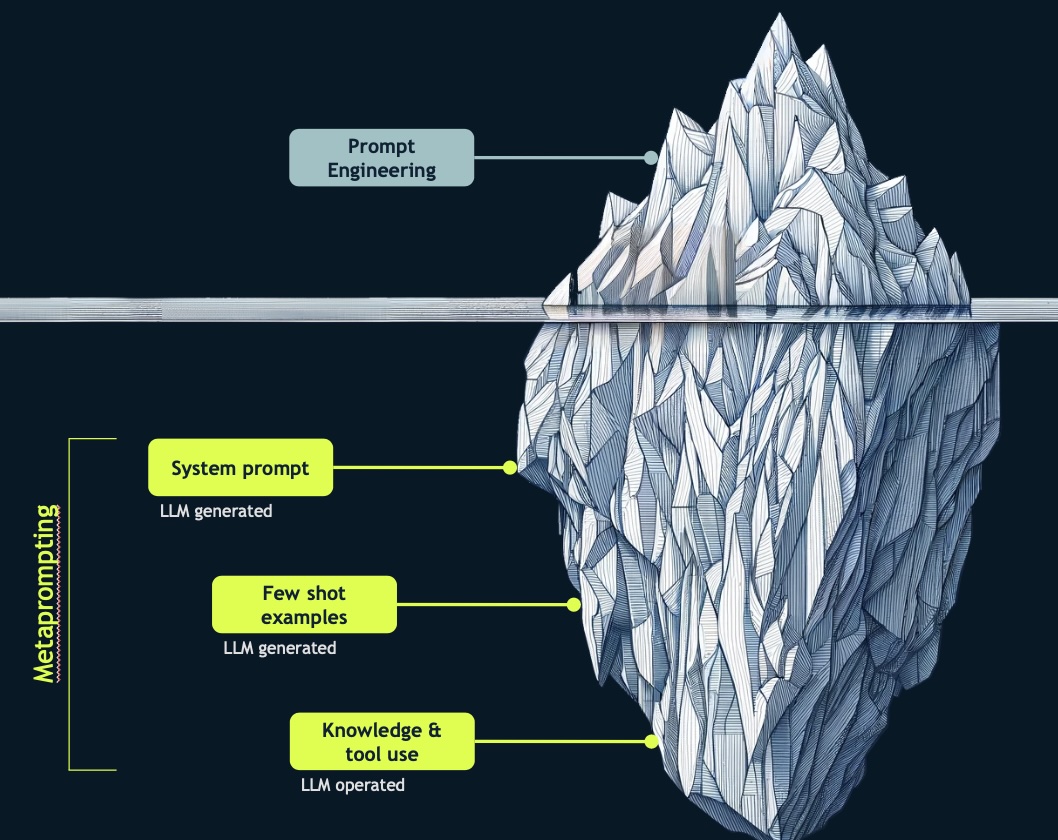
Prompt Engineering to Meta Prompting
In its early days, prompt engineering was relatively straightforward, involving simple back-and-forth interactions between a human and a large language model (LLM). However, the practice has evolved significantly, becoming more complex and sophisticated.
Source: tomoro.ai
Here are some key concepts:
System Prompt: This involves providing the model with specific instructions and defining its role and personality. The system prompt sets clear guidelines on how the model should perform tasks, akin to giving detailed instructions to a human.
Few-Shot Examples: This technique involves demonstrating tasks to the model rather than merely instructing it. By providing a few examples, we show the LLM how to perform the task, helping it understand and replicate the desired actions.
Knowledge & tool use: This involves carefully designing procedures to encourage the model’s access to knowledge and tools. It ensures that the model can effectively use the available resources to achieve the desired outcomes.
One notable distinction between agent-based workflows and retrieval-augmented generation (RAG) applications is the autonomy given to the LLM. In agent-based workflows, the LLM is empowered to decide which tools to use and how to use them, enhancing its capability and flexibility.
“Prompt engineering is dead. Long live meta prompting,” said Phelps. This reflects the shift in how we approach the field. Meta prompting involves using AI to generate the system prompt, few-shot examples, and procedural routines. It’s a “promptception,” where a meta prompt guides the model to create its own prompts. This approach has proven highly effective in recent production-based systems, streamlining the process and leveraging the model’s capabilities to a greater extent.
Use Cases
AGENT 1: AMPLIFY
The challenge was how to bring consumer ideas to life creatively, safely, and on brand. This is not an easy proposition when you’re dealing with a generative AI-based system. To overcome this, Phelps’ firm used Amplify, which leverages Azure OpenAI to power its processes.
Amplify
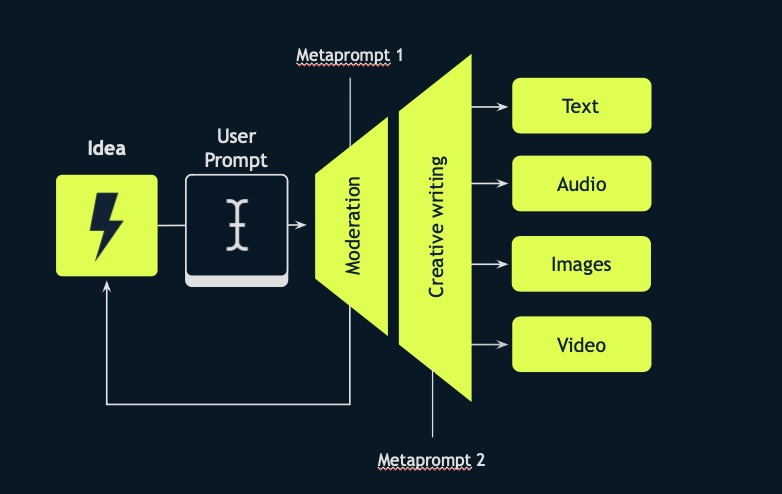
The agent creates higher quality content by amplifying human creative output, safely and effectively.
Source: tomoro.ai
Amplify allows users to submit their ideas, which are then processed through a series of stages to produce a final, high-quality output. The idea was implemented for Red Bull, where users can propose their dream day with a famous Red Bull athlete.
How does this work?
1. Idea Submission and Initial Feedback: Users start by submitting their dream day idea. Initially, the AI provides feedback, suggesting improvements to make their submission more compelling. This feedback is generated using a prompt conditioned by 10-20 examples of user inputs and AI responses. The AI’s feedback is designed to be encouraging, enthusiastic, and brand-safe, which is more challenging than it appears.

Source: tomoro.ai
2. Iteration and Improvement: Users can refine their ideas based on AI’s suggestions. The AI continues to provide positive reinforcement as the idea becomes more detailed and engaging.

Source: tomoro.ai
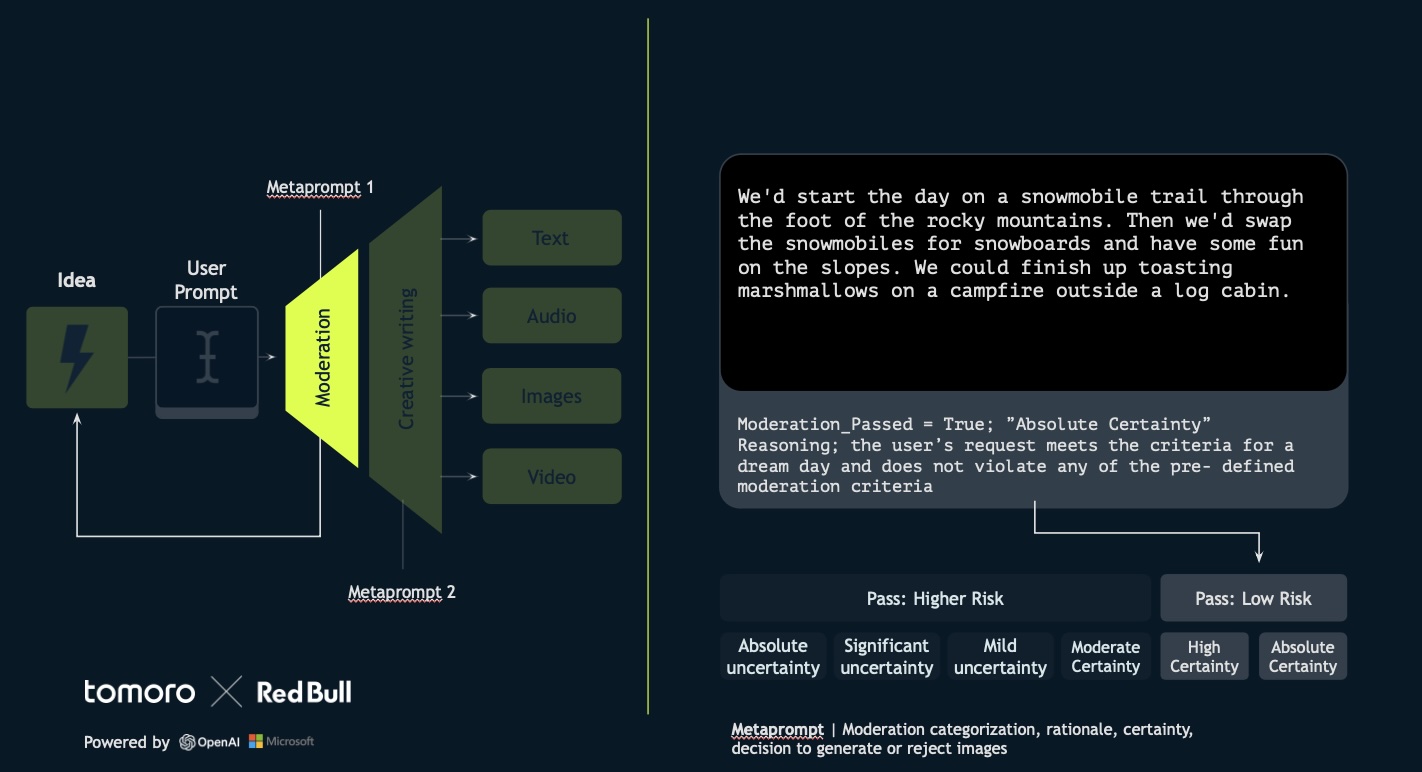
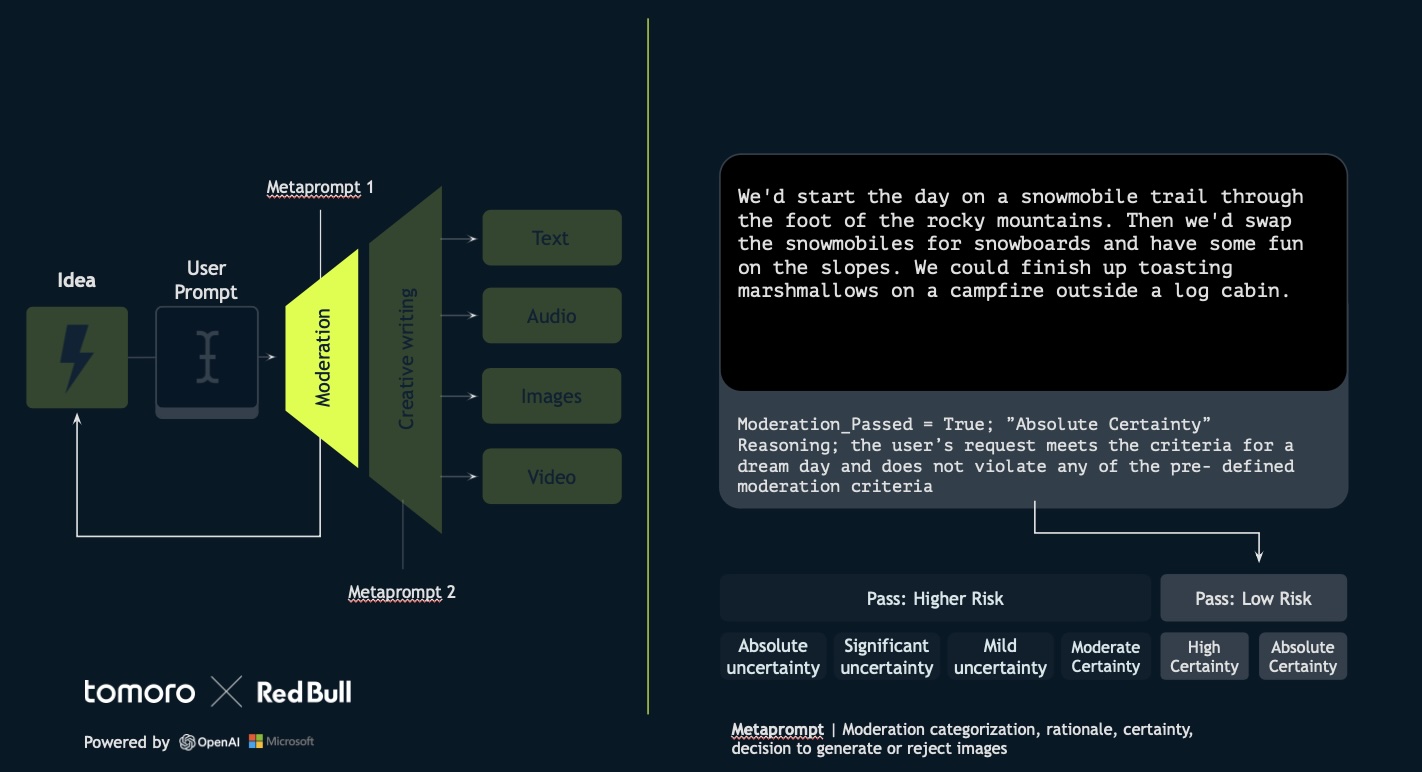
3. Moderation Pipeline: To ensure brand safety, user input doesn’t go straight into image generation. We have developed a robust moderation pipeline. This involves moderation, categorization, rationale, certainty, and an autonomous decision by the large language model on whether to generate or reject the image prompt. The system was trained using thousands of prompts— close to 1,000 adversarial, 1,000 borderline, and 1,000 allowable—to create a dataset of 50-60 few-shot examples, ensuring the AI can balance creativity with safety effectively.
“It’s a delicate balancing act between allowing creativity, keeping the brand safe, and disallowing anything that’s not safe for work,” said Phelps.
Source: tomoro.ai
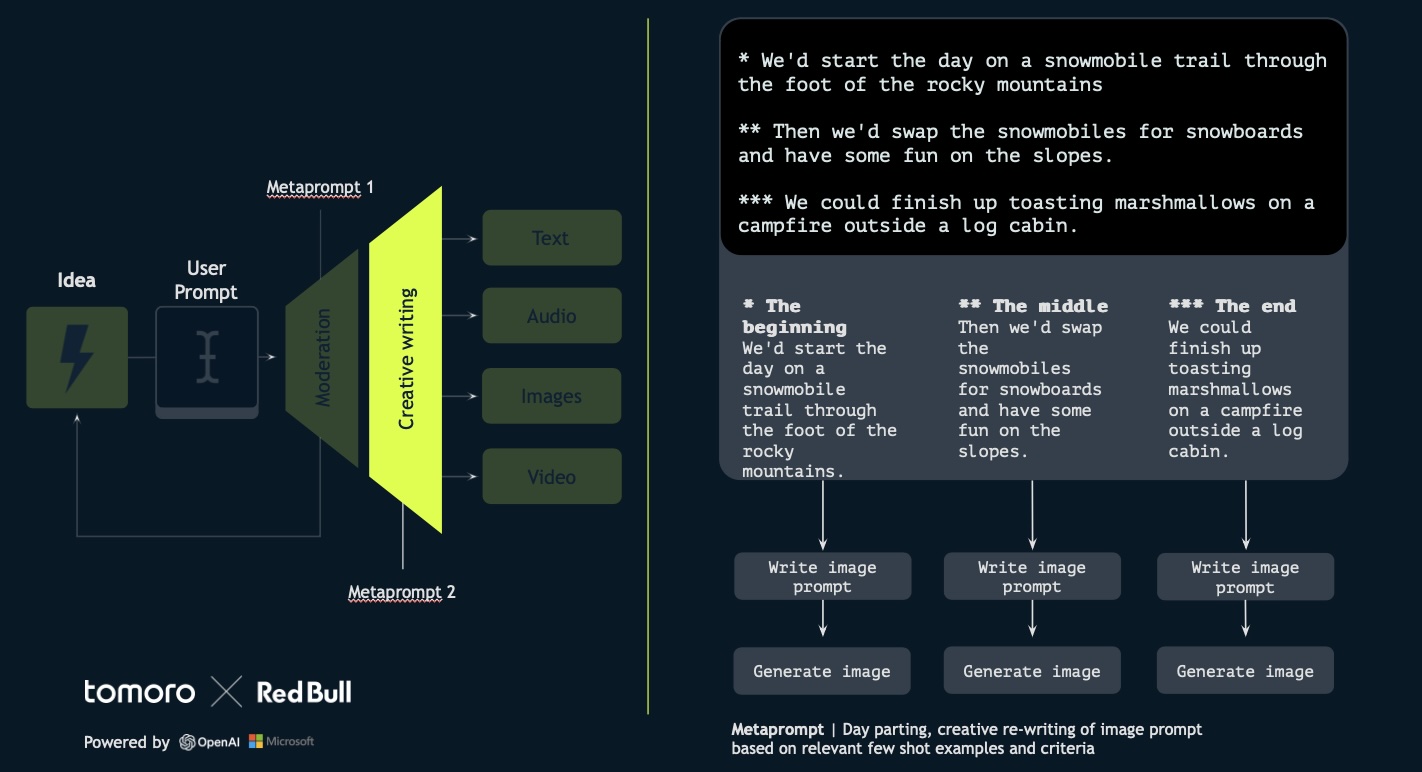
4. Creative Writing Meta-Prompt: Even with an improved user prompt, humans aren’t always perfect at prompting image models. The creative writing meta-prompt then takes the refined user input and enhances it further. This involves “day parting”—breaking the scene into beginning, middle, and end—and adding descriptive adjectives to improve the quality of prompts for the DALL-E model used for image generation.
Source: tomoro.ai
5. Final Output: This process results in three separate image prompts derived from the single input. The final images are then generated, and users with the best ideas can see their dream day brought to life visually. The best idea might even be realized in reality.
“Amplify is all about amplifying human creativity in a brand-safe way. It’s not about replacing human creativity,” added Phelps.

Source: tomoro.ai
AGENT 2: CONFORM
The idea here is how to ensure accurate and interpretable model outputs in strict regulatory settings.
LLMs are often seen as black boxes, but recent research provides interesting principles for building systems that require a high level of explainability beyond what standard models offer.
Conform
The agent provides fully inspectable, information-dense, reliable, and high-quality outputs suitable for the most sensitive enterprise workflows.
Source: tomoro.ai
Here’s how Conform works:
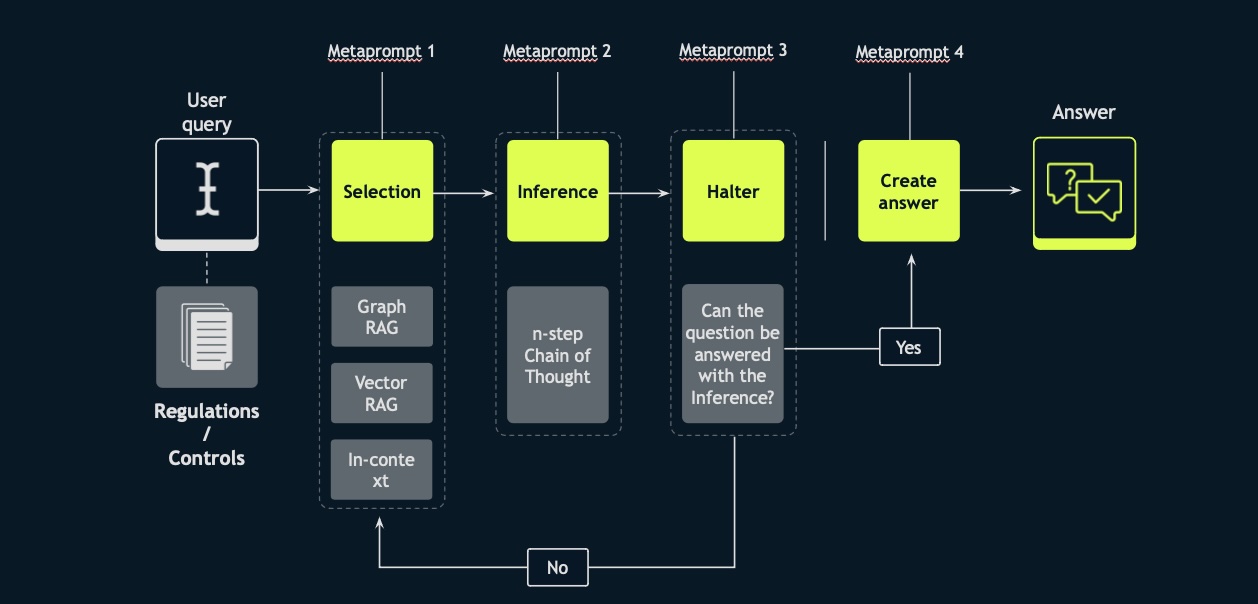
Initial Query and Dataset: We start with a user query and a dataset. This dataset can include regulations, controls, or any relevant documentation. This forms the foundation of the use cases.
Selection: The first model, Selection, determines the appropriate retrieval technique. This could be graph-based retrieval augmented generation, vector-based retrieval augmented generation, or, as LLMs and their context windows advance, directly using the entire document in context.
Inference: The second meta-prompted agent, Inference, performs chain-of-thought reasoning based on the information selected by the Selection model. This module does not see the original user query, so, there is a natural language causal reasoning trace from Selection to Inference.
Halter: The third module assesses whether the question can be answered with the inferences made. If yes, it generates and presents the answer to the user, including the reasoning process. If not, it reverts to the selection or retrieval stage for further information.
This is useful for use cases where you need a level of explainability and quality that goes beyond a simple or naive AI-based application. Conform delivers fully inspectable, information-dense, reliable, and high-quality outputs, suitable for the most sensitive enterprise workflows.
LLMs represent a significant technological advancement with the potential to aid research and understanding in various fields. However, they also require careful consideration of their limitations and their ethical challenges. When structured with prompts, human interaction patterns, and appropriate guardrails, LLMs can simulate helpful, accurate, and trustworthy assistants.
For enterprises looking for a solution, Phelps said, “AI agents are the largest potential driver of competitive advantage.”
__________________________
This article is adapted from a keynote address by Albert Phelps, Co-founder and Director, R&D at tomoro.ai delivered at NextTech Summit on May 29, 2024. Professor Munther A. Dahleh, Director of the MIT Institute for Data, Systems, and Society was a speaker at the inaugural edition of the summit. The keynote has been edited for clarity and length by Liji Varghese, Associate Editor, MIT SMR Middle East. Boston Consulting Group (BCG) was the Knowledge Partner and AstraTech was the Gold Sponsor for the summit.
References
- Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, Shmargaret Shmitchell, “On the Dangers of Stochastic Parrots:Can Language Models Be Too Big?”
- Blaise Agüera y Arcas, Peter Norvig, “Artificial General Intelligence Is Already Here”, Noema, published Oct 10, 2023, www.noemamag.com


